
M3DeTR: Multi-representation, Multi-scale, Mutual-relation 3D Object Detection with Transformers
Tianrui Guan*, Jun Wang*, Shiyi Lan, Rohan Chandra, Zuxuan Wu, Larry Davis, Dinesh Manocha
Published in Winter Conference on Applications of Computer Vision, 2022
Abstract
We present a novel architecture for 3D object detection, M3DeTR, which combines different point cloud representations (raw, voxels, bird-eye view) with different feature scales based on multi-scale feature pyramids. M3DeTR is the first approach that unifies multiple point cloud representations, feature scales, as well as models mutual relationships between point clouds simultaneously using transformers. We perform extensive ablation experiments that highlight the benefits of fusing representation and scale, and modeling the relationships. Our method achieves state-of-the-art performance on the KITTI 3D object detection dataset and Waymo Open Dataset. Results show that M3DeTR improves the baseline significantly by 1.48% mAP for all classes on Waymo Open Dataset. In particular, our approach ranks 1st on the well-known KITTI 3D Detection Benchmark for both car and cyclist classes, and ranks 1st on Waymo Open Dataset with single frame point cloud input.
| Paper | Code | Dataset |
|---|---|---|
| M3DeTR | Code | KITTI / Waymo |
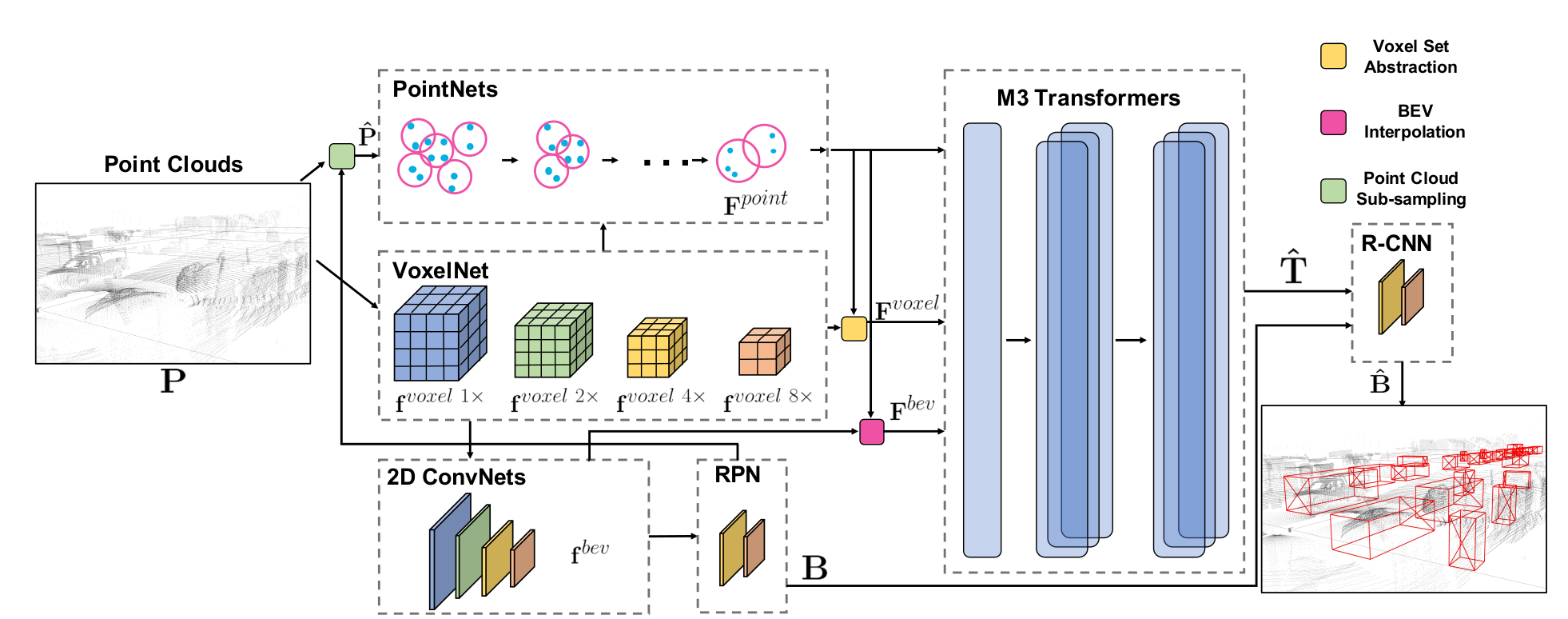
Network Architecture: M3DeTR is a transformer based framework for object detection in a coarse- to-fine manner. It consists of three parts. PointNets, VoxelNet, and 2D ConvNets modules enable individual multi-representation feature learning. M3 Transformers enable inter-intra multi-representation, multi-scale, multi-location feature attention. With the Region Pro- posal Network (RPN), the initial box proposals are generated. R-CNN captures and refines region-wise feature representations from M3 transformer output to improve detection performance.
![]()
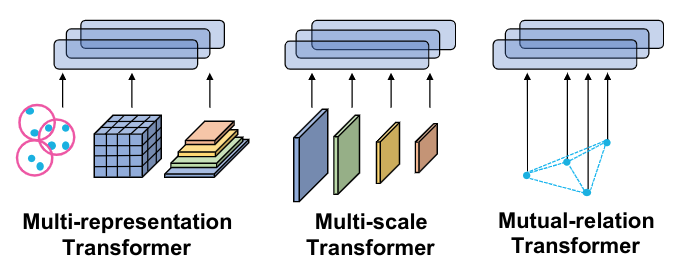
M3 Transformers consist of two parts: a multi-representation and multi-scale transformer, and a mutual-relation transformer. Multi-representation and multi-scale transformer takes the different feature embedding and generates enriched cross-representations and cross-scales embedding. Further, the mutual-relation transformer models point-wise feature relationship to extract the refined features.
Please cite our work if you found it useful,
@InProceedings{Guan_2022_WACV,
author = {Guan, Tianrui and Wang, Jun and Lan, Shiyi and Chandra, Rohan and Wu, Zuxuan and Davis, Larry and Manocha, Dinesh},
title = {M3DETR: Multi-Representation, Multi-Scale, Mutual-Relation 3D Object Detection With Transformers},
booktitle = {Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)},
month = {January},
year = {2022},
pages = {772-782}
}